

The PDF Challenge:
Despite the rapid pace of digital transformation and the advancements in technologies, the usage of PDF documents to keep data standardized and secure is ubiquitous. Whether you are a small business or a large enterprise; you work in accounting, operations, finance, marketing, sales or procurement departments – the need to extract and transfer data from a large variety of PDF documents including purchase orders, invoices, contracts, expense reports, financial reports, product catalogs, phone bills, bank statements, income statements, contact lists to other CRM, Marketing, Sales, finance, support, operations & accounting apps has been increasing.
Furthermore, these documents are can be large in number, complex, long and custom built for each business process. Accessing the content in the diverse set of PDF documents has not only been a challenge but also an impedance to the ongoing digital transformation revolution. Although the core technology required to extract and manipulate the contents of a PDF document – Optical Character Recognition (OCR) technology has been around for a long period of time, the availability of OCR and application of this technology has seen lower user adoption than is required for scaling the demands of the ongoing digital transformation.
Modern businesses need modern solutions
The explosion of SaaS apps in cloud has been at the forefront of driving digital transformation for businesses of all sizes and given modern businesses the agility, speed and flexibility they need to build solutions for the future. Therefore it is only natural that Workato and Docparser, two technologies that share the same DNA – native cloud, pure SaaS, API driven and requiring zero coding come together to give a highly robust and scalable solution for automating your document based business processes.
You can train your custom PDF parser using Docparser’s powerful parsing engine. Define custom parsing rules without writing any code to extract tabular data, text from scanned documents, fixed and variable layout documents. Docparser solves the challenge of moving your data from the PDF document to where it belongs – CRM systems, ERP, databases and cloud apps. Now using the Docparser connector you can harness the same power of the Docparser parsing engine and build recipes to automate any business process that requires transferring data from PDF documents to your Salesforce, Marketo, Intacct, ServiceNow, Quickbase, SurveyMonkey, Zendesk, JIRA applications.
You can also build recipes to automate moving documents stored as attachments in Salesforce Case data, Zendesk tickets, JIRA tickets, Twilio MMS or files from cloud drives (e.g. Dropbox, Google Drive, Box, OneDrive etc.) to Docparser account for parsing. These two methods give you immense flexibility and power to use the combination of Workato and Docparser to convert the static data living inside those PDF documents to a stream of information that flows through your digital enterprise.
You will soon find your ability to automate your document business process is only limited by your imagination!
Taking the First Step – Docparser Parsing Rules

As with the most memorable journeys mankind has taken, the first step is the most critical and essential. For automating your business process using PDF documents, the first step is to sign up for a Docparser account. After you have created an account with Docparser:
- Create your document parser– Give a unique name to identify the document parser e.g. Purchase Order Data
- Upload sample documents – The layout, column headers and positions of the sample must match that of the final set of documents that will be parsed by Docparser
- Create parsing rules – these rules are run on multiple sample document to train the parser learn parsing rules to extract data from an incoming document.
Next create the Docparser connection in your Workato account by specifying the DocParser API key for your account.
The recipe building process with the Docparser connection is no different from how you connect with other applications. The current Docarser connection offers 1 Trigger and 1 Action to build the recipes.
Pulling the Trigger
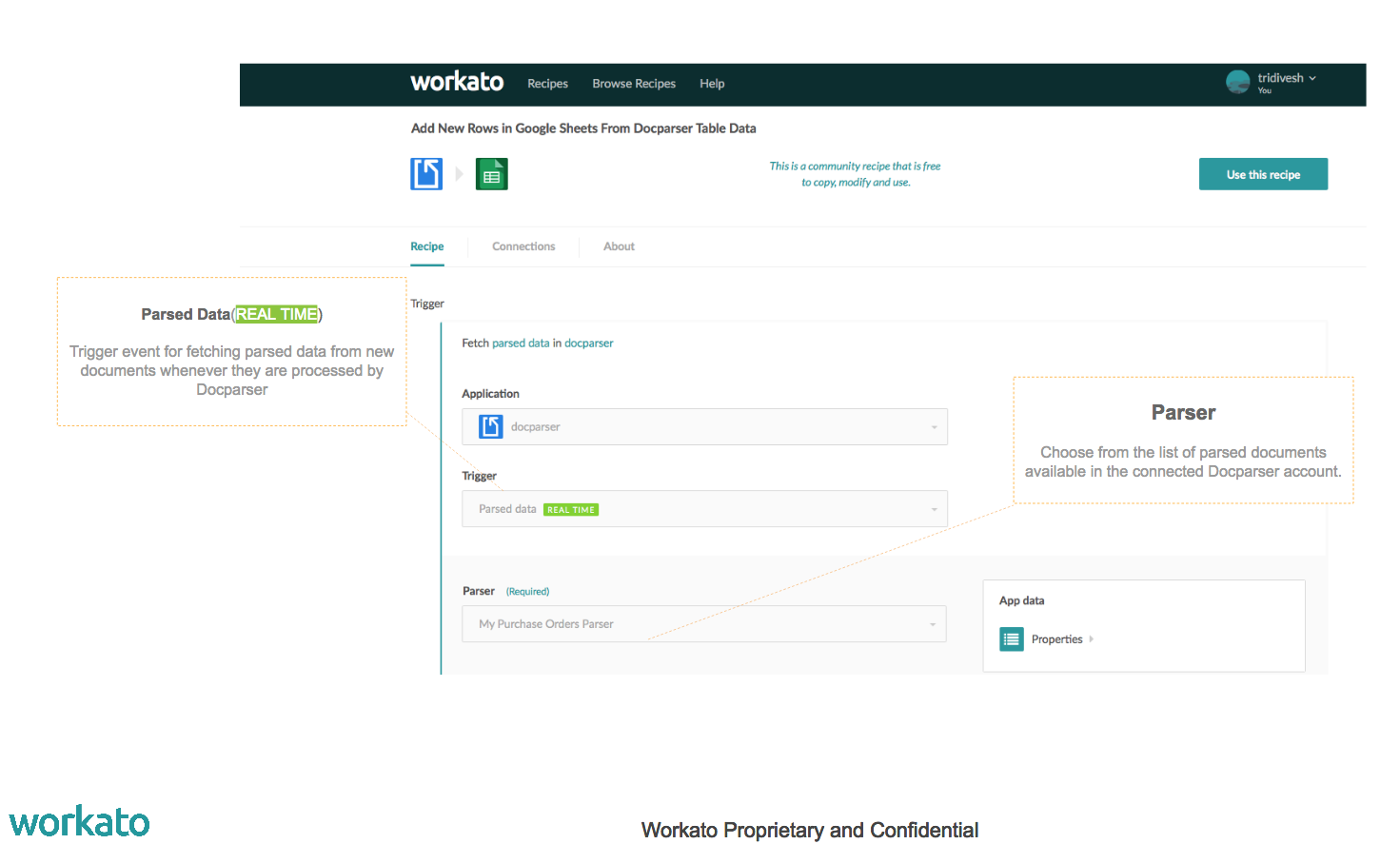
Parsed Data (Real Time):
- Trigger event for fetching parsed data from new documents whenever they are processed by Docparser.
- This trigger will start the recipe anytime a new document is parsed by Docparser e.g. data from a new purchase order document was processed.
- The trigger is useful when automating processes which are expecting data from a PDF document parsed by Docparser and moving that data into downstream applications.
Examples:
- Docparser to Quickbase: Fetch parsed data from Docparser and update Quickbase

- Docparser to Google Sheets: Fetch parsed data from Docparser and add new rows in Google Sheets

Taking Actions
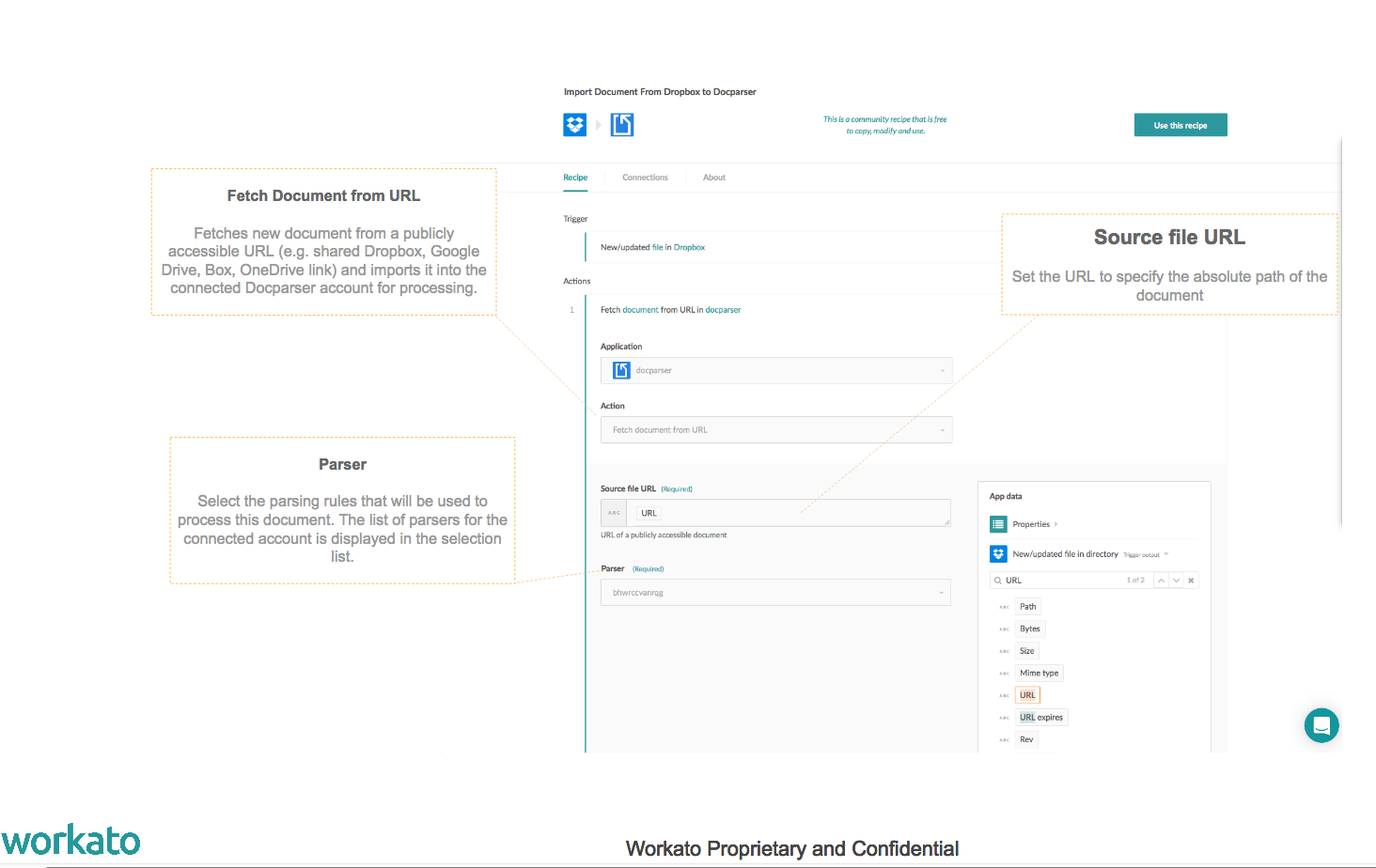
Fetch Document from URL:
- This action is particularly useful when you are automating the process of importing files stored in a variety of cloud drive locations to Docparser.
- This action allows you to import documents from any publicly available URL to Docparser.
- Typical use cases include importing files from Dropbox, Box, Google Drive, OneDrive etc. to Docparser
Examples:
- Dropbox to Docparser: Import files from a dropbox folder to Docparser

- Box to Docparser: Import files from a Box folder to Docparser
